Contrastive Transliteration Correction
Model
This model is used to perform spelling correction on Indic words generated by the Transliteration Generation model in the English-to-Indic decoding task and by the CTC Gesture Path Decoder in the Indic-to-Indic decoding task. Word embeddings like GLoVe and Word2Vec generate vector representations of words that map semantic similarities to geometrical closeness. The ELMo network creates contextual word embeddings that depend on the entire sequence of words. It treats a sentence as a sequence of words and uses CNN and LSTM layers for feature extraction to obtain the word embeddings.
In this work, we propose a method to create vector representations of words that are indicative of closeness in their character sequences by using the ELMo network for generating character embeddings by processing each word as a sequence of characters. The resulting embeddings would depend on other characters in the word and their relative positioning, thus making it suitable for spelling comparison. As seen in the Figure, the generated character embeddings of a word are summed together and then min-max normalized to obtain an encoding for the word. This process is followed to obtain an encoding for the misspelt word, w and for each word v in the vocabulary . Then, the model computes the squared difference between the encodings of the word w and each of the words v to obtain a distance vector,
,where |E| is the ELMo embedding dimension.
where represents the word encoding for a word
.
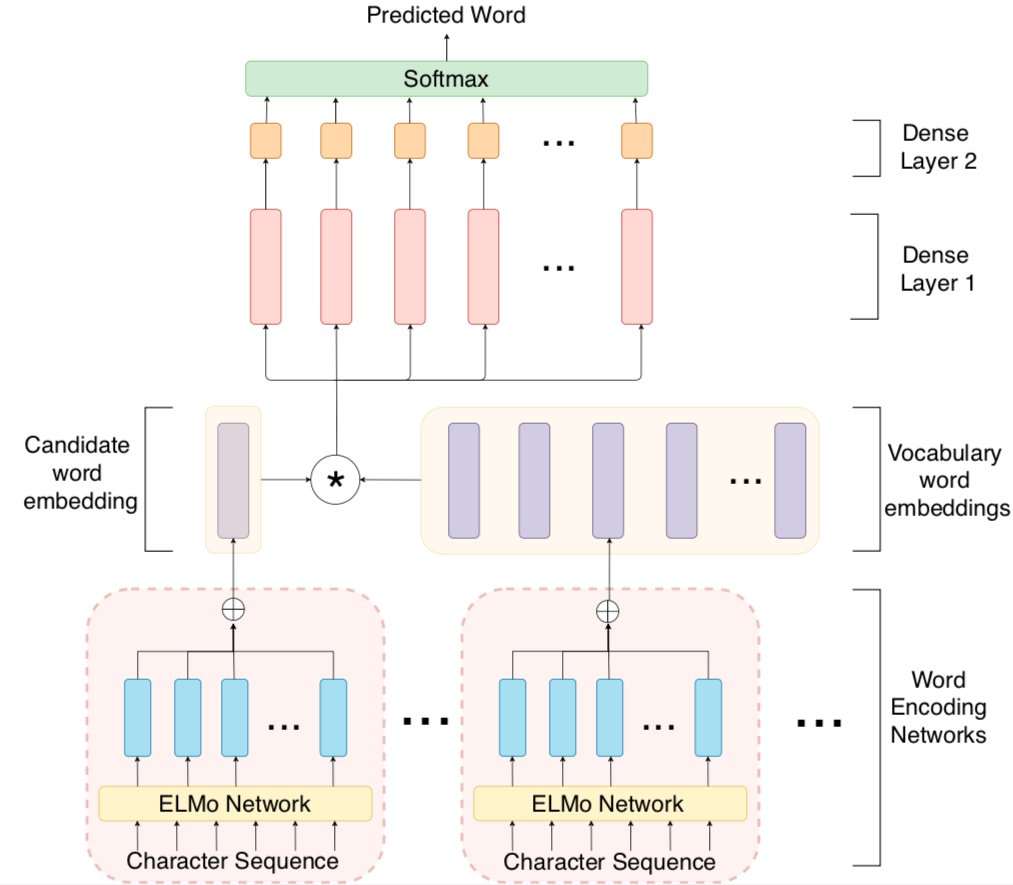
Distance vectors for each word pair is passed through two fully connected (dense) layers to obtain a 1-D distance metric, . The word v* from the vocabulary for which distance metric,
is the smallest is chosen as the corrected word. To accomodate words that are not part of the vocabulary, we place an upper threshold on
and force the model to output the prediction from the Transliteration Generation module if it exceeds this threshold.